
By
Samir Amin
Published
Read Time:
Building the Deep Research Agent: Turning Engineering Data Into Intelligence
What is the deep research agent?
Our agent, Wooly AI, analyzes all of your engineering metrics and data to answer any question about your team's productivity. It reasons across code output, review patterns, AI usage, quality metrics, and team dynamics to surface insights that would take hours of manual analysis to uncover, if you could uncover them at all.
The core difference: Traditional analytics are reactive. They show what you've configured them to show. It’s exploratory. It understands your question, identifies which metrics matter, gathers relevant data from multiple sources, and synthesizes an answer that's contextual to your specific team.
The data aggregation advantage
Weave consolidates metrics from across your project management tools, version control systems, and productivity platforms. Most engineering teams have their data fragmented across 5-10 different tools. When you ask "how can I ship faster?", answering that question requires pulling together code output from GitHub, project context from Jira or Linear and AI usage data from Cursor, Claude Code and more.
DRA operates on this unified data layer. The agent sees your entire engineering system holistically, which means it can discover insights that span multiple tools, insights that are literally impossible to find when your data lives in silos.
This data aggregation is our moat. The agentic architecture is sophisticated, but the real value is having comprehensive, integrated data to reason over.
Current state: Wooly AI is deployed as a research and reporting agent, excelling at deep analytical questions and comprehensive performance reports.
Who it's for: Engineering leaders and team leads making data-driven decisions about velocity, quality, and team health.
What Wooly AI does best
1. Anomaly Detection: "What's Wrong Right Now?"
Instead of manually scanning dashboards for red flags, ask DRA to analyze everything and surface what's actually unusual:
A PR that took 28 days to merge when your team average is 4 days
An engineer whose output suddenly dropped 70% from their baseline
A team's review cycle time that spiked 3x in the last week
A repository that went from 50 commits/week to 12 with no explanation
DRA finds these patterns across any time range: last week, last month, last quarter and explains what changed.
2. Performance Analysis: "How Do I Ship Faster?"
This question requires a systematic analysis of your entire system. DRA doesn't just look at velocity in isolation; it finds the bottlenecks:
Example analysis: "Your org's average review wait time increased from 8 hours to 38 hours over the last month. DRA identifies that 60% of cross-team reviews now route through your Platform team, they're doing 4.2x more reviews than any other team. The bottleneck isn't code quality or review thoroughness; it's that Platform became a single point of dependency after the org restructure. Recommended action: Distribute architecture review responsibility across senior engineers in each team."
The agent examines:
Code output patterns across repositories, teams, and authors
Review dynamics: Who's reviewing what? Where are the queues forming?
Quality vs. velocity trade-offs: Reverted PRs, bug introduction rates, technical debt accumulation
AI adoption impact: Teams using AI-assisted coding showing 30% higher output, should other teams adopt similar tools?
3. Multi-Dimensional Correlation Analysis
Real insights live at the intersections:
Did velocity drop because of increased review burden, or because the team added two junior engineers who need more mentoring?
Is your highest-performing team actually introducing more bugs per line of code than slower teams?
Are teams with high AI adoption also showing improved code quality, or are they trading quality for speed?
Did your switch from feature branches to trunk-based development actually improve cycle time, or did it just shift where the delays happen?
DRA can analyze these questions across:
Code output: repository, team, and author levels
Review patterns: cycle times, quality signals, bottleneck identification
AI metrics: Usage correlation with output and quality
Quality indicators: Reverted PRs, bug patterns, technical debt
Time-series trends: Week over week, month over month, quarter over quarter
Beyond Simple Lookups
DRA isn't optimized for simple fact retrieval. "What was the last PR John pushed?" is better answered by looking at GitHub directly. DRA excels at synthesis, questions requiring multiple data sources, trend identification, and contextualized recommendations.
How It Works: Built for Intelligence
Why This Problem Needs Agents
Engineering management operates on incomplete, unstructured information spread across multiple systems. Should this task be assigned to Alice or Bob? Which bugs should be prioritized? Is this new review process helping or hurting? These decisions require:
Context awareness across multiple data sources
Pattern recognition that humans might miss
Reasoning about causality, not just correlation
Synthesis of insights into actionable recommendations
Traditional rule-based systems can't handle this complexity. Dashboards can show you the data but can't reason about it. This is precisely where agentic AI excels: taking messy, multi-dimensional data and extracting signal from noise.
The Multi-Node Agentic Workflow
Wooly AI is an orchestrated workflow where different stages operate with different contexts and constraints.
Context-Aware Phases:
Understanding: Classify the query (simple vs. deep research)
Context Gathering: Collect relevant user/team metadata
Research: Gather data from multiple sources
Analysis: Identify patterns and correlations
Reporting: Synthesize findings into actionable insights
Each phase receives only the context relevant to that stage. This is critical. By hiding irrelevant information, we keep the agent focused and reduce hallucination risk.
Intelligent Query Routing: Not all questions need the same computational effort. DRA automatically classifies queries:
Simple queries (e.g., "Show me commits from the mobile team last week") → Single-agent, streamlined workflow
Deep research queries (e.g., "Why did velocity drop and what should we do about it?") → Parallel research system
Auto-classification achieves 90%+ accuracy. Users can also manually toggle modes.
Parallel Research Agents: For complex queries, DRA deploys up to six parallel research agents. Here's a real example:
Query: "Why did velocity drop 30% last month?"
DRA spawns 6 agents:
Agent 1: Analyze code output trends across all teams (finds Mobile team output dropped 60%)
Agent 2: Examine review cycle time patterns (identifies 2x longer review waits)
Agent 3: Investigate deployment frequency changes (no significant change)
Agent 4: Check for infrastructure or tooling changes
Agent 5: Correlate with team composition changes (discovers 2 senior engineers on PTO)
Agent 6: Examine external dependencies and blockers (identifies API dependency delays)
Each agent iterates independently: high-level analysis → detailed drill-down → refinement. Results synthesize into: "Velocity drop primarily driven by Mobile team (60% decrease). Root causes: CI/CD migration created 4-day deployment delays, compounded by two senior engineers on PTO during critical sprint. Platform team velocity actually increased 15%. Recommendation: Prioritize Mobile CI/CD stabilization; consider cross-team pairing to reduce PTO impact."
This parallel approach delivers both speed and depth. Sequential exploration would be slow; multiple agents exploring different angles simultaneously gets comprehensive answers fast.
Infrastructure and Design Choices
Tech stack: Python for the agent service and MCP server (fast iteration, rich ecosystem for agentic workflows), integrating with our Go backend. FastAPI handles the agent service orchestration.
Architecture:
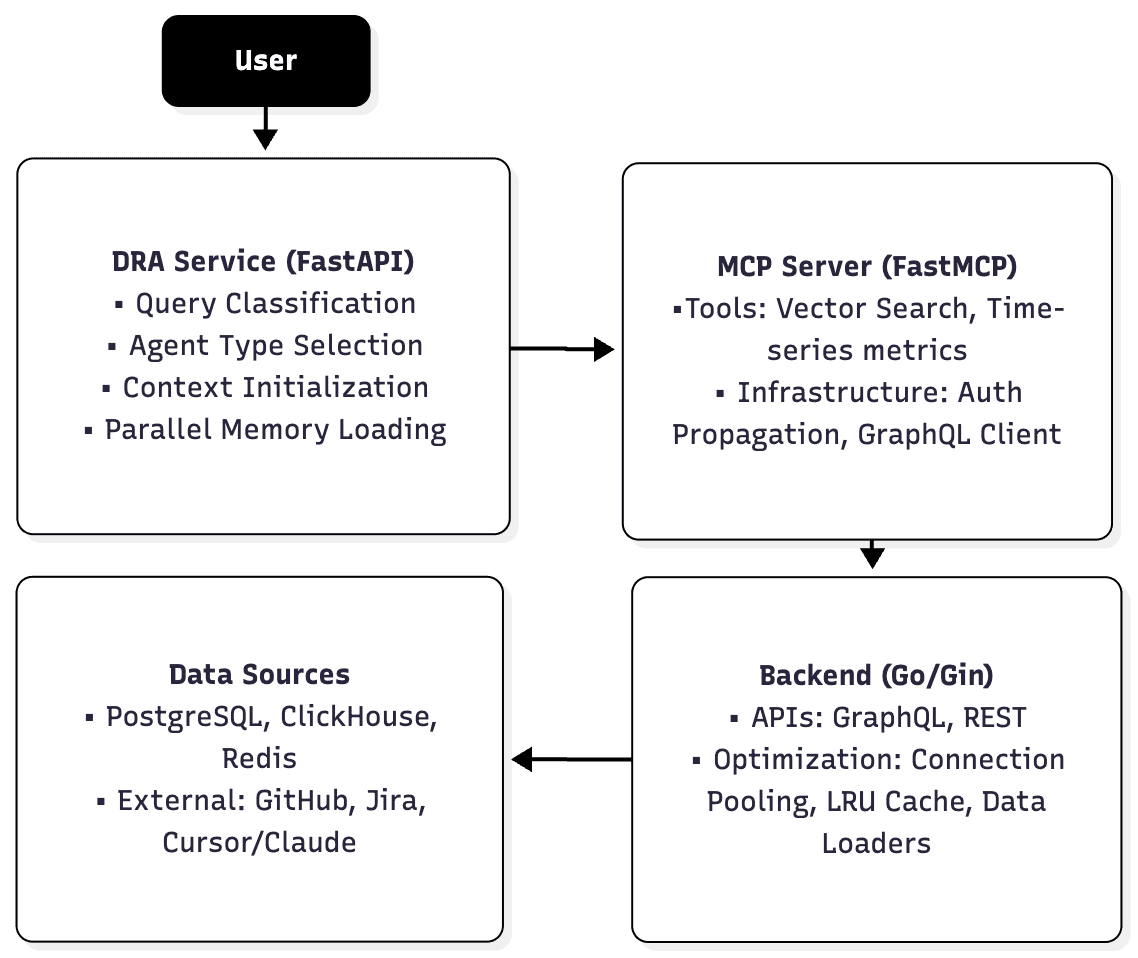
The Model Context Protocol (MCP) provides a clean abstraction for data access. Our Go backend remains the source of truth for all metrics, handling authentication and retrieval.
Internal-only by design: Both the agent and MCP server require authentication. Only verified users within our platform can query DRA. This gives us security and control as we iterate rapidly. Many companies are building public MCP servers; we may get there, but our focus now is nailing the authenticated use case. The agent is only acting on company data. The only data that is used beyond your team's connections are the percentiles and benchmarks for all our metrics. These are only used for comparison purposes, not direct data querying.
Read-only operations: DRA currently only reads data, it doesn't modify, create, or delete anything. This is a deliberate constraint as we build trust and understand the right interaction patterns. Write operations unlock massive value but introduce risk. We're moving carefully.
The Roadmap: From Analysis to Action
We're building toward DRA as the central nervous system for engineering operations. Here's the trajectory:
Near-term (Next 3-6 months):
Anomaly detection system integration: Continuous monitoring that proactively alerts you to unusual patterns before you have to ask
Enhanced pattern recognition: Early warning signs of burnout, predictors of quality issues, indicators of process breakdown
Expanded metric coverage: Deeper integration with more tools and richer signal extraction
Medium-term (6-12 months):
Write capabilities: Creating tickets, assigning tasks, updating project state
Automated project management: Setting up projects with learned patterns from your previous work
Intelligent bug discovery: Analyzing PRs for common error patterns and automatically creating remediation tickets
The vision:
Imagine this workflow: "Create a new project for the mobile team's Q2 initiative, using the same structure as the backend refactor project. Set up initial tasks and assign them based on who has capacity and relevant expertise."
DRA executes:
Reads your previous project configurations, extracts patterns
Analyzes current team capacity, skills, and workload distribution
Creates project structure in your PM tool
Generates and assigns initial tasks to appropriate team members
Configures workflows, integrations, and tracking dashboards
Sets up automated status reporting
This automation reclaims hours each week spent on project administration, ticket grooming, and process coordination. The logical extension: DRA becomes your engineering operations partner, continuously optimizing processes, identifying opportunities, and executing routine management tasks while you focus on strategy and people.
Try It and Shape It
We're early, DRA is powerful today at research and analysis, but most of what we just described is ahead of us. We're sharing this because we believe in building with community feedback.
We want to hear about:
The question you wish you could ask your engineering data: What insight would change how you make decisions?
The pattern that signals trouble in your org: What subtle indicator always means something's wrong (that no tool catches)?
The management task you'd gladly hand to an agent tomorrow: What's tedious enough that you'd trust automation?
The workflow DRA should enable: What integration or capability would transform your team?
The engineering data landscape is vast, and the possibilities for agentic intelligence are genuinely exciting. We have strong hypotheses, but we know we're missing things. Your feedback shapes where this goes.
Share your ideas, your use cases, your wild what-if scenarios. This technology is powerful, and we're still discovering all the ways it can help teams ship better software faster.
Try the Deep Research Agent: www.workweave.dev/agent
" transform="translate(53 38)" width="1391.0019999999997px"/><path d="M 748.501 0 C 829.12 0 904.371 18.049 968.074 49.28 C 1020.663 75.06 1085.983 84.064 1147.583 79.071 C 1158.383 78.196 1169.353 77.747 1180.443 77.747 C 1355.393 77.747 1497.003 189.223 1497.003 326.499 C 1497.003 463.775 1355.393 575.251 1180.443 575.251 C 1169.353 575.251 1158.383 574.802 1147.583 573.927 C 1085.983 568.933 1020.663 577.937 968.074 603.72 C 904.371 634.951 829.12 652.999 748.501 652.999 C 667.88 652.999 592.629 634.951 528.925 603.72 C 476.336 577.937 411.017 568.933 349.415 573.927 C 338.483 574.811 327.52 575.253 316.553 575.251 C 141.607 575.252 0 463.776 0 326.5 C 0 189.224 141.607 77.748 316.553 77.748 C 327.65 77.748 338.614 78.197 349.416 79.072 C 411.017 84.065 476.337 75.062 528.925 49.279 C 592.629 18.05 667.88 0 748.501 0 Z" fill="transparent" height="652.999px" id="WKnkxlJxQ" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" width="1497.003px"/><path d="M 644.001 0 C 713.37 0 778.118 13.963 832.927 38.124 C 878.186 58.075 934.397 65.042 987.403 61.179 C 996.703 60.501 1006.133 60.154 1015.683 60.154 C 1090.933 60.154 1159.033 81.714 1208.303 116.546 C 1257.583 151.379 1288.003 199.453 1288.003 252.5 C 1288.003 305.547 1257.583 353.621 1208.303 388.454 C 1159.033 423.286 1090.933 444.846 1015.683 444.846 C 1006.133 444.846 996.703 444.499 987.403 443.821 C 934.398 439.958 878.186 446.924 832.927 466.875 C 778.118 491.036 713.37 505 644.001 505 C 574.631 505 509.882 491.036 455.073 466.875 C 409.814 446.924 353.602 439.958 300.593 443.821 C 291.184 444.506 281.752 444.848 272.318 444.846 C 197.073 444.846 128.972 423.286 79.696 388.454 C 30.418 353.621 0 305.547 0 252.5 C 0 199.453 30.418 151.379 79.696 116.546 C 128.972 81.714 197.073 60.154 272.318 60.154 C 281.866 60.154 291.299 60.501 300.593 61.179 C 353.602 65.042 409.814 58.075 455.073 38.124 C 509.882 13.964 574.631 0 644.001 0 Z" fill="transparent" height="505px" id="dQQ4CBK9S" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(104 74)" width="1288.0030000000004px"/><path d="M 591.5 0 C 655.218 0 714.69 11.922 765.032 32.548 C 806.607 49.582 858.241 55.53 906.932 52.231 C 915.472 51.653 924.132 51.356 932.902 51.356 C 1002.022 51.357 1064.572 69.763 1109.832 99.497 C 1155.092 129.234 1183.002 170.258 1183.002 215.5 C 1183.002 260.742 1155.092 301.766 1109.832 331.503 C 1064.572 361.237 1002.022 379.643 932.902 379.644 C 924.132 379.644 915.472 379.347 906.932 378.769 C 858.241 375.47 806.607 381.418 765.032 398.452 C 714.69 419.079 655.218 431 591.5 431 C 527.781 431 468.308 419.079 417.965 398.452 C 376.39 381.418 324.757 375.47 276.066 378.769 C 267.529 379.347 258.863 379.644 250.093 379.644 C 180.977 379.643 118.427 361.237 73.171 331.503 C 27.911 301.766 0 260.742 0 215.5 C 0 170.258 27.911 129.234 73.171 99.497 C 118.427 69.763 180.977 51.357 250.093 51.356 C 258.863 51.356 267.529 51.653 276.066 52.231 C 324.757 55.53 376.39 49.582 417.965 32.548 C 468.308 11.921 527.781 0 591.5 0 Z" fill="transparent" height="431px" id="QTNF4coLA" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(157 111)" width="1183.0020000000002px"/><path d="M 538.5 0 C 596.513 0 650.659 10.045 696.492 27.424 C 734.348 41.778 781.36 46.789 825.693 44.01 C 833.566 43.517 841.453 43.271 849.342 43.272 C 912.272 43.272 969.212 58.782 1010.412 83.832 C 1051.622 108.887 1077.002 143.433 1077.002 181.5 C 1077.002 219.567 1051.622 254.113 1010.412 279.168 C 969.212 304.218 912.272 319.728 849.342 319.728 C 841.352 319.728 833.466 319.478 825.693 318.99 C 781.36 316.211 734.348 321.222 696.492 335.576 C 650.659 352.955 596.513 363 538.5 363 C 480.486 363 426.339 352.955 380.506 335.576 C 342.65 321.222 295.638 316.211 251.305 318.99 C 243.533 319.478 235.643 319.728 227.659 319.728 C 164.73 319.728 107.784 304.218 66.585 279.168 C 25.378 254.113 0 219.567 0 181.5 C 0 143.433 25.378 108.887 66.585 83.832 C 107.784 58.782 164.73 43.272 227.659 43.272 C 235.644 43.272 243.532 43.522 251.305 44.01 C 295.637 46.789 342.65 41.778 380.506 27.424 C 426.339 10.045 480.486 0 538.5 0 Z" fill="transparent" height="363px" id="LUddM0Cto" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(210 145)" width="1077.002px"/><path d="M 486 0 C 538.363 0 587.236 8.058 628.603 21.999 C 662.773 33.514 705.206 37.534 745.219 35.305 C 752.327 34.91 759.445 34.712 766.564 34.713 C 823.362 34.713 874.762 47.156 911.942 67.248 C 949.142 87.351 972.002 115.04 972.002 145.5 C 972.002 175.96 949.142 203.649 911.942 223.752 C 874.762 243.844 823.362 256.287 766.564 256.287 C 759.356 256.287 752.235 256.086 745.219 255.695 C 705.206 253.466 662.773 257.486 628.603 269.001 C 587.236 282.942 538.363 291 486 291 C 433.636 291 384.762 282.942 343.395 269.001 C 309.225 257.486 266.792 253.466 226.779 255.695 C 219.763 256.086 212.642 256.287 205.435 256.287 C 148.634 256.287 97.235 243.844 60.054 223.752 C 22.854 203.649 0 175.96 0 145.5 C 0 115.04 22.854 87.351 60.054 67.248 C 97.235 47.156 148.634 34.713 205.435 34.713 C 212.642 34.713 219.763 34.914 226.779 35.305 C 266.792 37.534 309.225 33.514 343.395 21.999 C 384.763 8.058 433.636 0 486 0 Z" fill="transparent" height="291px" id="oUG2urEET" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(262 181)" width="972.002px"/><path d="M 429.5 0 C 475.784 0 518.984 5.961 555.547 16.273 C 585.748 24.791 623.25 27.764 658.614 26.115 C 664.898 25.823 671.189 25.678 677.48 25.679 C 727.692 25.679 773.122 34.883 805.982 49.745 C 838.892 64.628 859.002 85.085 859.002 107.5 C 859.002 129.915 838.892 150.372 805.982 165.255 C 773.122 180.117 727.692 189.321 677.48 189.321 C 671.109 189.321 664.815 189.173 658.614 188.884 C 623.25 187.235 585.748 190.208 555.547 198.726 C 518.984 209.038 475.785 215 429.5 215 C 383.214 215 340.015 209.038 303.451 198.726 C 273.251 190.208 235.749 187.235 200.385 188.884 C 194.184 189.173 187.89 189.321 181.519 189.321 C 131.31 189.321 85.879 180.117 53.018 165.255 C 20.111 150.372 0 129.915 0 107.5 C 0 85.085 20.111 64.628 53.018 49.745 C 85.879 34.883 131.31 25.679 181.519 25.679 C 187.89 25.679 194.184 25.826 200.385 26.115 C 235.749 27.764 273.25 24.791 303.451 16.273 C 340.015 5.961 383.214 0 429.5 0 Z" fill="transparent" height="215px" id="kwmo_rb6T" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(319 219)" width="859.002px"/><path d="M 369.5 0 C 409.33 0 446.505 3.975 477.969 10.851 C 503.951 16.528 536.216 18.509 566.642 17.41 C 572.052 17.215 577.465 17.118 582.878 17.119 C 626.087 17.119 665.184 23.257 693.462 33.165 C 707.602 38.12 719.012 44.008 726.872 50.522 C 734.742 57.039 739.002 64.131 739.002 71.5 C 739.002 78.869 734.742 85.961 726.872 92.478 C 719.012 98.992 707.602 104.88 693.462 109.835 C 665.184 119.743 626.087 125.881 582.878 125.881 C 577.396 125.881 571.979 125.783 566.642 125.59 C 536.216 124.491 503.951 126.472 477.969 132.149 C 446.505 139.025 409.33 143 369.5 143 C 329.669 143 292.494 139.025 261.029 132.149 C 235.047 126.472 202.782 124.491 172.356 125.59 C 166.947 125.785 161.534 125.882 156.121 125.881 C 112.912 125.881 73.815 119.743 45.539 109.835 C 31.398 104.88 19.989 98.992 12.126 92.478 C 4.26 85.961 0 78.869 0 71.5 C 0 64.131 4.26 57.039 12.126 50.522 C 19.989 44.008 31.398 38.12 45.539 33.165 C 73.815 23.257 112.912 17.119 156.121 17.119 C 161.603 17.119 167.019 17.217 172.356 17.41 C 202.781 18.509 235.047 16.528 261.029 10.851 C 292.494 3.975 329.669 0 369.5 0 Z" fill="transparent" height="143px" id="ZDUWPKa3g" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(379 255)" width="739.0020000000002px"/><path d="M 306.5 0 C 339.554 0 370.405 2.153 396.518 5.878 C 418.068 8.952 444.831 10.026 470.071 9.431 C 474.5 9.326 478.996 9.272 483.546 9.272 C 519.406 9.272 551.855 12.598 575.326 17.967 C 587.065 20.652 596.531 23.843 603.049 27.368 C 606.312 29.131 608.812 30.965 610.482 32.842 C 612.162 34.715 613.002 36.606 613.002 38.5 C 613.002 40.394 612.162 42.285 610.482 44.158 C 608.812 46.035 606.312 47.869 603.049 49.632 C 596.531 53.157 587.065 56.348 575.326 59.033 C 551.855 64.402 519.406 67.728 483.546 67.728 C 478.996 67.728 474.501 67.674 470.072 67.569 C 444.832 66.974 418.068 68.047 396.518 71.121 C 370.405 74.846 339.554 77 306.5 77 C 273.445 77 242.594 74.846 216.481 71.121 C 194.931 68.047 168.167 66.974 142.927 67.569 C 138.498 67.674 134.003 67.728 129.453 67.728 C 93.593 67.728 61.144 64.402 37.673 59.033 C 25.934 56.348 16.468 53.157 9.95 49.632 C 6.69 47.869 4.191 46.035 2.512 44.158 C 0.836 42.285 0 40.394 0 38.5 C 0 36.606 0.836 34.715 2.512 32.842 C 4.191 30.965 6.69 29.131 9.95 27.368 C 16.468 23.843 25.934 20.652 37.673 17.967 C 61.144 12.598 93.593 9.272 129.453 9.272 C 134.003 9.272 138.498 9.326 142.927 9.431 C 168.167 10.026 194.93 8.952 216.48 5.878 C 242.593 2.153 273.445 0 306.5 0 Z" fill="transparent" height="77.00000000000006px" id="KDODgiTvq" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(442 288)" width="613.002px"/><path d="M 242.5 0 C 268.67 0 293.098 0.774 313.776 2.111 C 330.821 3.214 351.996 3.599 371.967 3.386 C 375.524 3.348 379.08 3.329 382.637 3.329 C 411.03 3.329 436.727 4.522 455.32 6.451 C 464.619 7.416 472.125 8.563 477.297 9.832 C 479.887 10.467 481.865 11.126 483.184 11.795 C 483.844 12.13 484.313 12.455 484.611 12.759 C 484.907 13.061 485 13.307 485 13.5 C 485 13.693 484.907 13.939 484.611 14.241 C 484.313 14.545 483.844 14.87 483.184 15.205 C 481.865 15.874 479.887 16.533 477.297 17.168 C 472.125 18.437 464.619 19.584 455.32 20.549 C 436.727 22.478 411.03 23.671 382.637 23.671 C 379.034 23.671 375.474 23.652 371.967 23.614 C 351.996 23.401 330.821 23.786 313.776 24.889 C 293.098 26.226 268.67 27 242.5 27 C 216.329 27 191.901 26.226 171.223 24.889 C 154.177 23.786 133.003 23.401 113.031 23.614 C 109.524 23.652 105.964 23.671 102.362 23.671 C 73.969 23.671 48.272 22.478 29.679 20.549 C 20.38 19.584 12.874 18.437 7.702 17.168 C 5.112 16.533 3.134 15.874 1.815 15.205 C 1.155 14.87 0.686 14.545 0.388 14.241 C 0.092 13.939 0 13.693 0 13.5 C 0 13.307 0.092 13.061 0.388 12.759 C 0.686 12.455 1.155 12.13 1.815 11.795 C 3.134 11.126 5.112 10.467 7.702 9.832 C 12.874 8.563 20.38 7.416 29.679 6.451 C 48.272 4.522 73.969 3.329 102.362 3.329 C 105.964 3.329 109.524 3.348 113.031 3.386 C 133.003 3.599 154.177 3.214 171.223 2.111 C 191.901 0.774 216.329 0 242.5 0 Z" fill="transparent" height="26.999999999999886px" id="g_28k_kKg" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgba(130, 130, 130, 0.3)" transform="translate(506 313)" width="485px"/></g></svg>)

By
Samir Amin
Published
The engineering intelligence platform for the AI era.
Trusted by engineering teams from seed stage to Fortune 500